Key lookup and RID lookup in SQL Server execution plans
Key lookup and RID lookup are very common operations in SQL server execution plans. Understanding these concepts is very important when we are tuning SQL queries for performance.
To better understand what we will discuss in this video, you need to have a good understanding of
Set up Employees table
Consider this Employees table
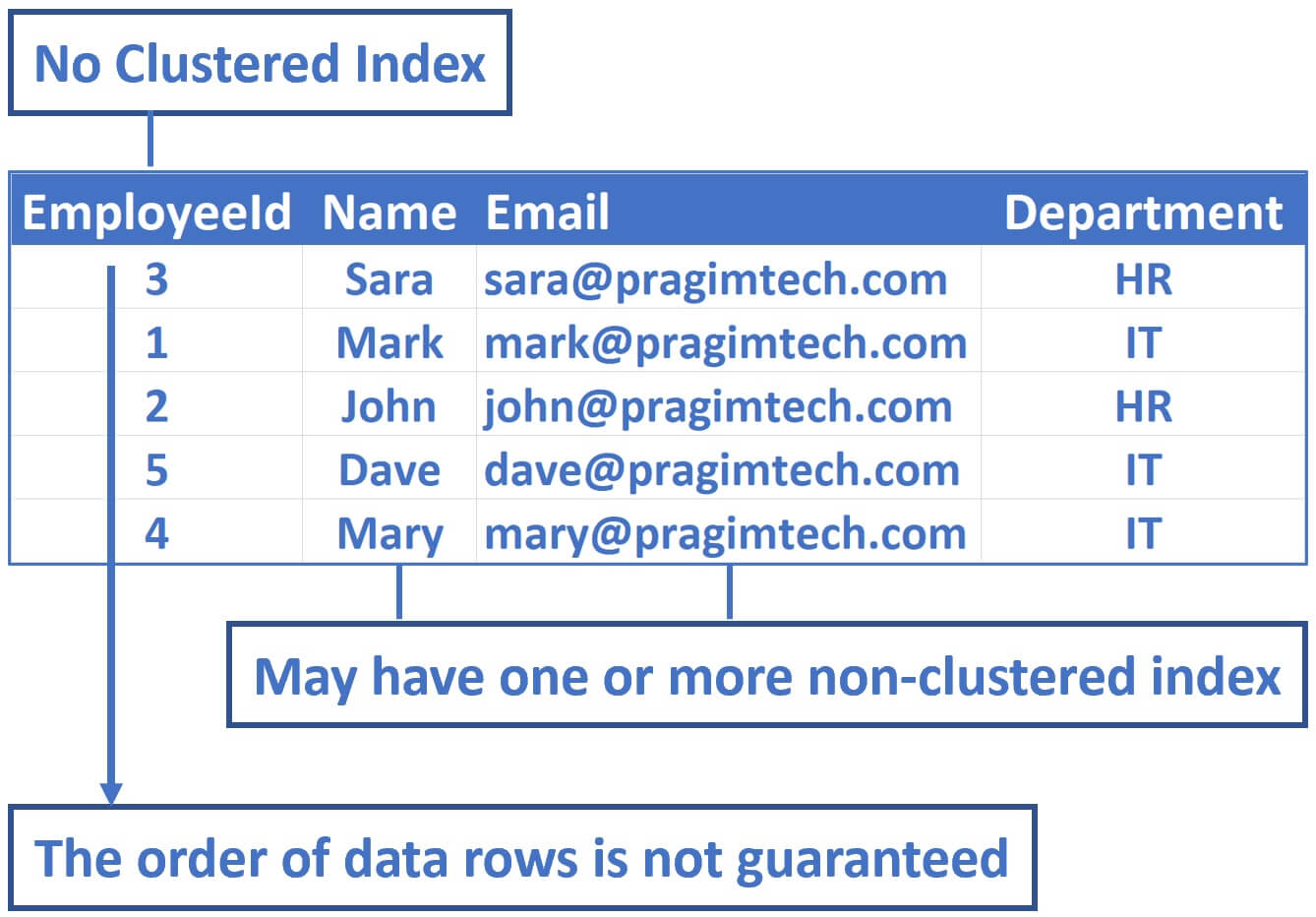
- There is no clustered index on this table
- This means the physical order in which data rows are stored in the table is not guaranteed
- A table without a clustered index is called a heap
- A heap table may have one or more non-clustered indexes
We discussed all these Heap Table concepts in our previous video. If you are new to heap tables, please check out the following video.
Script for Employees table
Create Table Employees
(
Id int identity,
[Name] nvarchar(50),
Email nvarchar(50),
Department nvarchar(50)
)
Go
SET NOCOUNT ON
Declare @counter int = 1
While(@counter <= 1000000)
Begin
Declare @Name nvarchar(50) = 'ABC ' + RTRIM(@counter)
Declare @Email nvarchar(50) = 'abc' + RTRIM(@counter) + '@pragimtech.com'
Declare @Dept nvarchar(10) = 'Dept ' + RTRIM(@counter)
Insert into Employees values (@Name, @Email, @Dept)
Set @counter = @counter +1
If(@Counter%100000 = 0)
Print RTRIM(@Counter) + ' rows inserted'
EndTable scan in execution plan
Execute the following SELECT query, with Include Actual Execution plan turned ON
Select * from Employees where Name = 'ABC 932000'From the execution plan, it's clear, a full table scan is used to find the data we are looking for.
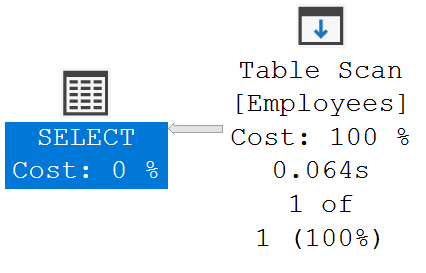
Notice, from the stats below, Number of rows read is 1M and Actual number of rows for all executions is 1. So, to get the 1 record we need SQL server has to read 1M reacords which obviously is extremely inefficient. Also notice, Estimated Subtree Cost is 11.4877 which is extremely high and there is a massive opportunity here to improve the performance by including a non-clustered index.

Heap table with a non-clustered index
The following query is searching employees by Name
Select * from Employees where Name='ABC 932000'So, create a non-clustered index on the Name column and then execute the SELECT query again.
Create nonclustered index IX_Employees_Name on Employees(Name)From the execution plan it's clear, SQL Server is using Index Seek instead of Table Scan.
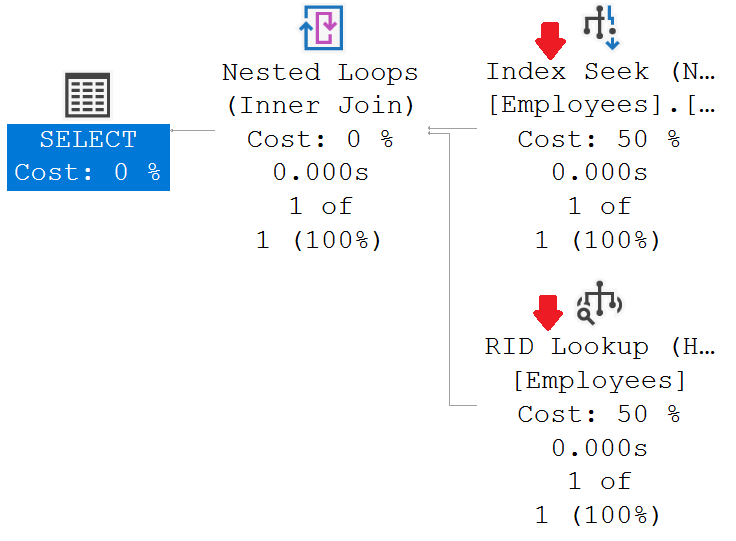
With the help of the non-clustered index on the Name column, SQL server is able to find that one record we want. Notice, both, Number of rows read and Actual number of rows for all executions is 1. Also, notice, the Estimated subtree cost is also massively reduced to 0.0032831.
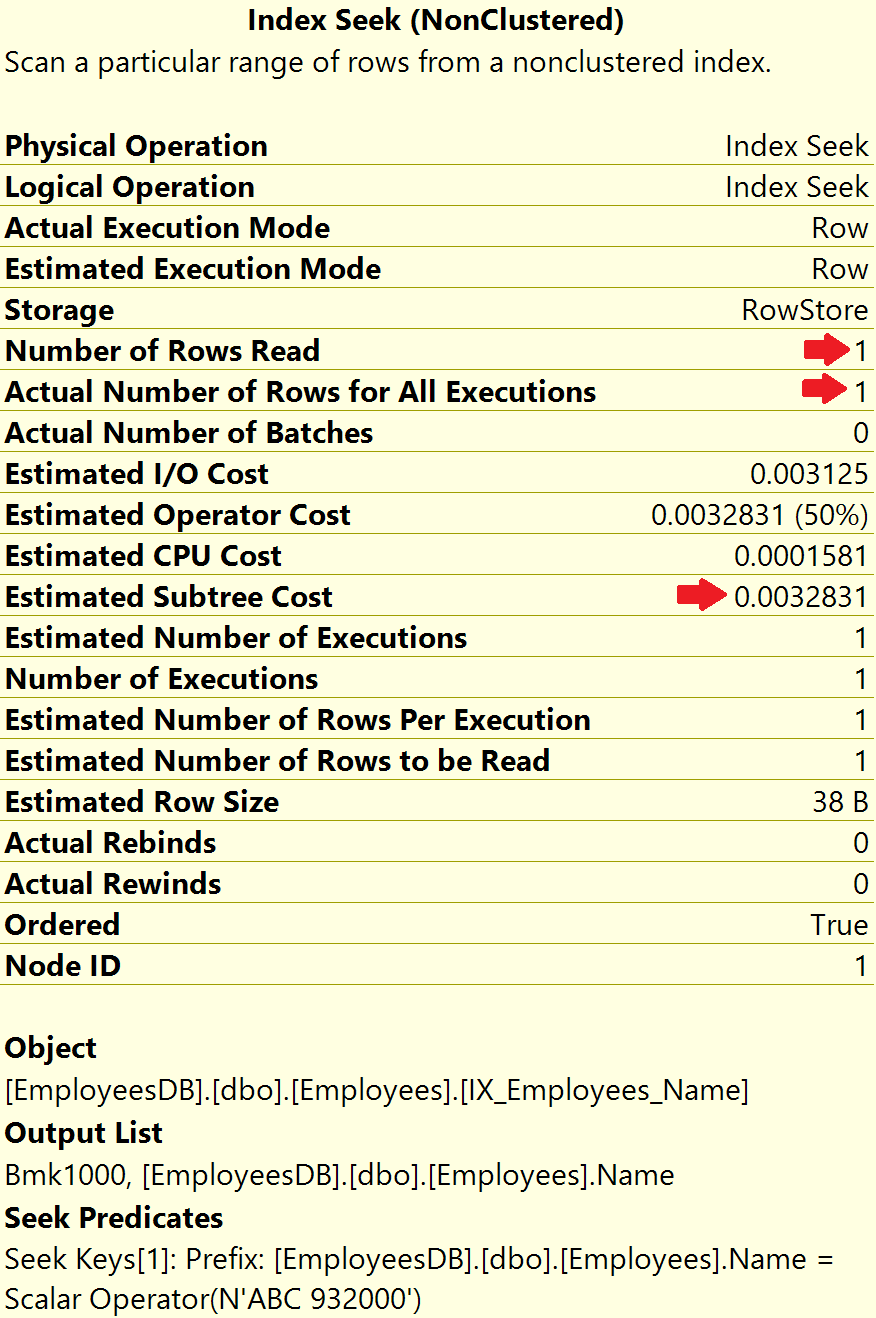
What is RID lookup in sql server execution plans
In the execution plan, along with Index Seek operation, we also have RID lookup operation. RID stands for Row ID.
Why do we need this Row ID look up operation? Well, in the non-clustered index we only have Name column and Row ID (RID), but we want the rest of the columns (EmployeeId, Email and Dept) as well from the Employees table. So, SQL Server uses the Row ID to lookup the respective row from the Employees table.
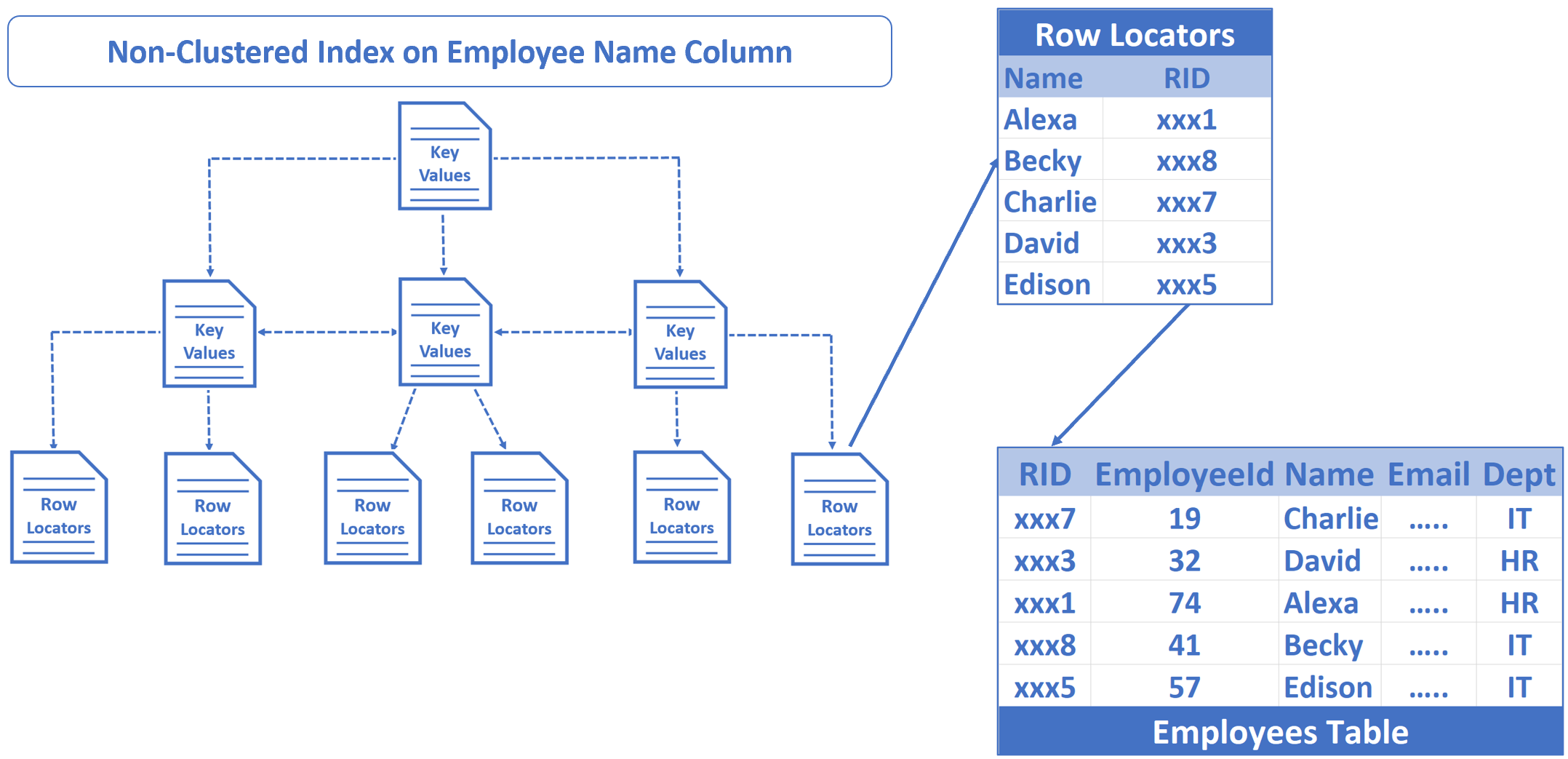
Execute Select Name from Employees where Name='ABC 932000' instead of Select * from Employees where Name='ABC 932000'. Notice, in the SELECT list, we only have Name column and the Non-clustered index already contains Name column. This means the index has everything the SELECT query needs and this is the reason, we don't have RID lookup operation in the execution plan now.

What is key lookup in sql server execution plans
Without a clustered index on the table, the data rows are not guaranteed to be stored in any specific order, but if we create a clusterd index, for example on employee Id column, the data in the table is physically stored in the sorted order of employee Id. If we zoom into one of the leaf nodes at the bottom of the tree, notice, Employee data rows are sorted by the Id column.
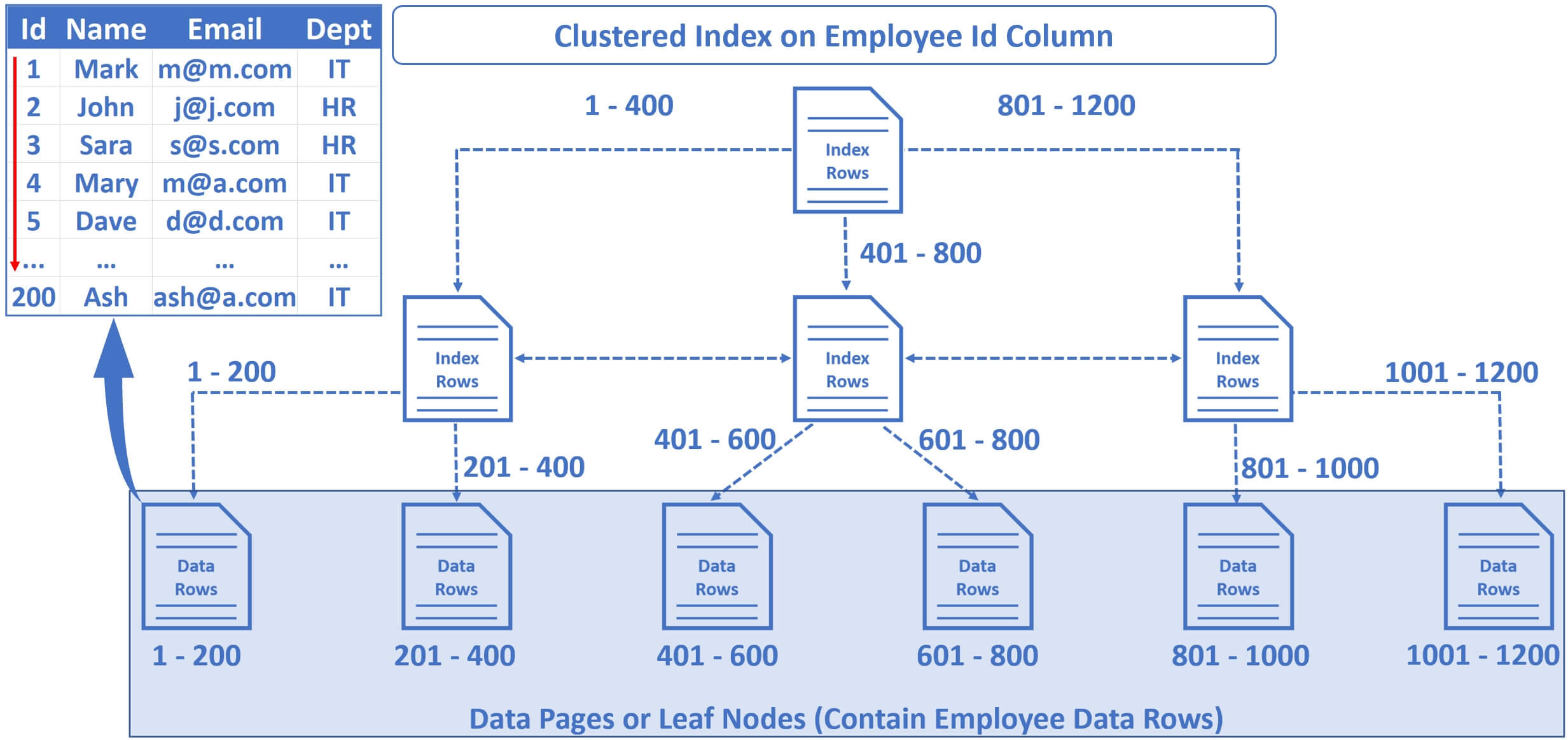
Create clusterd index on Id column
Create clustered index IX_Employees_Id on Employees(Id)Now, execute the SELECT statement again
Select * from Employees where Name = 'ABC 932000'Notice, now, in the execution plan, we have Key lookup instead of RID lookup.

Why? Well, the data rows in the Employees table are stored in the sorted order of EmployeeId column, because we have a clustered index on the Employee Id column now. We have a non-clustered index on the Employee Name column. So, if you zoom in to one of the row locators at the bottom of this non-clustered index tree, notice, Employee Names are sorted and stored in alphabetical order. Along with the name, we now have Employee Id in the index. SQL Server uses this Employee Id and with the help of the clustered index, the database engine quickly locates the respective employee record. Hence, we now have Key Lookup instead of RID lookup in the execution plan.
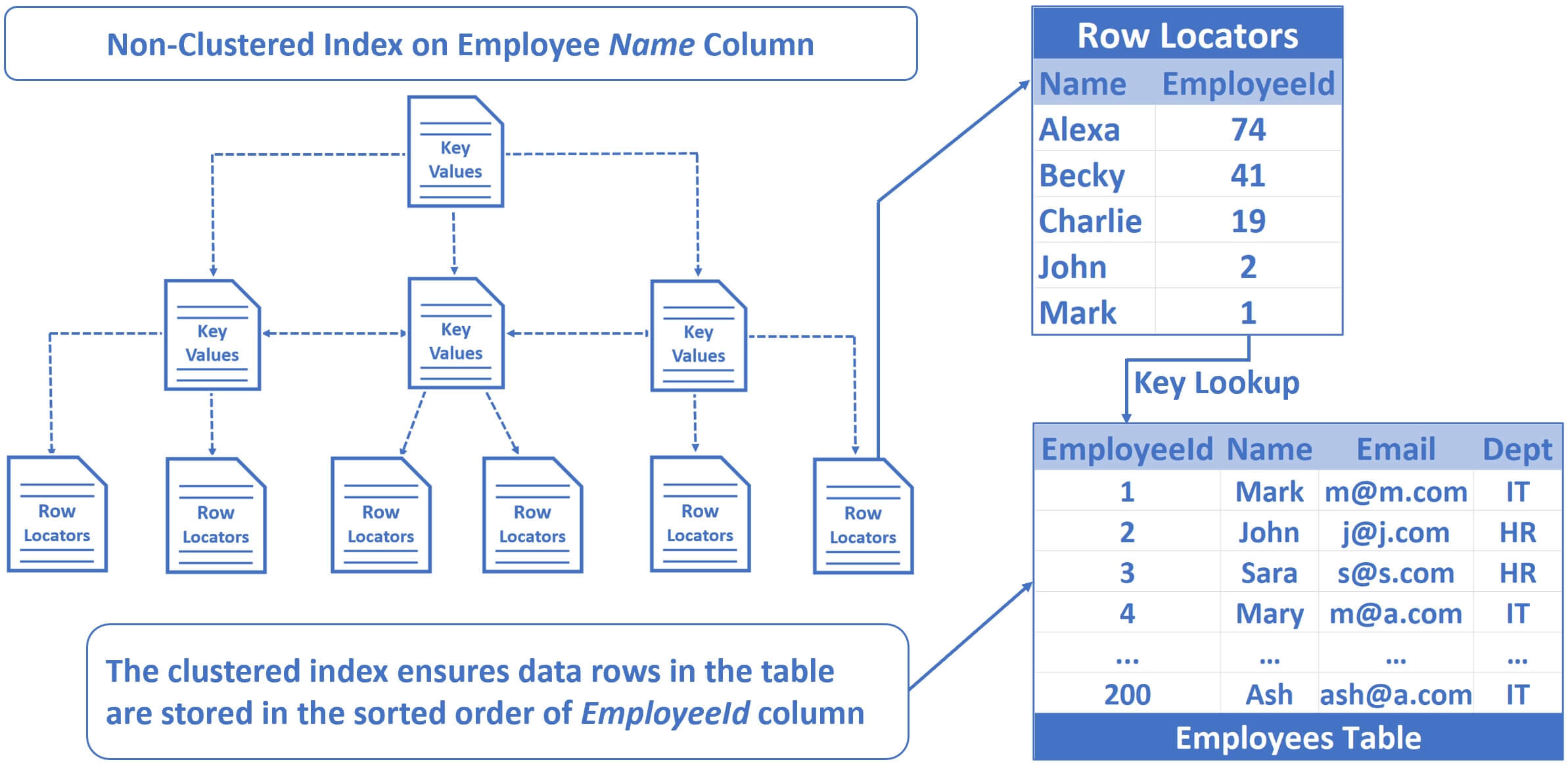
Now, execute the following query
Select Id, Name from Employees where Name = 'ABC 932000'Notice, in the execution plan, we only have Index Seek operation. We don't have Key Lookup, this is because, botht Id and Name column requested in the SELECT list are available in the index. Basically, the database engine has everything it needs in the index. There's no need to look up the data row in the Employees table. This is the reason we don't see Key Lookup in the execution plan.

What is better for performance - Key lookup or RID lookup
We have the Estimated Subtree Cost for both Key Lookup and RID Lookup side by side and it's the same - 0.0065704. This obviously means, for this example, both are same from performance standpoint
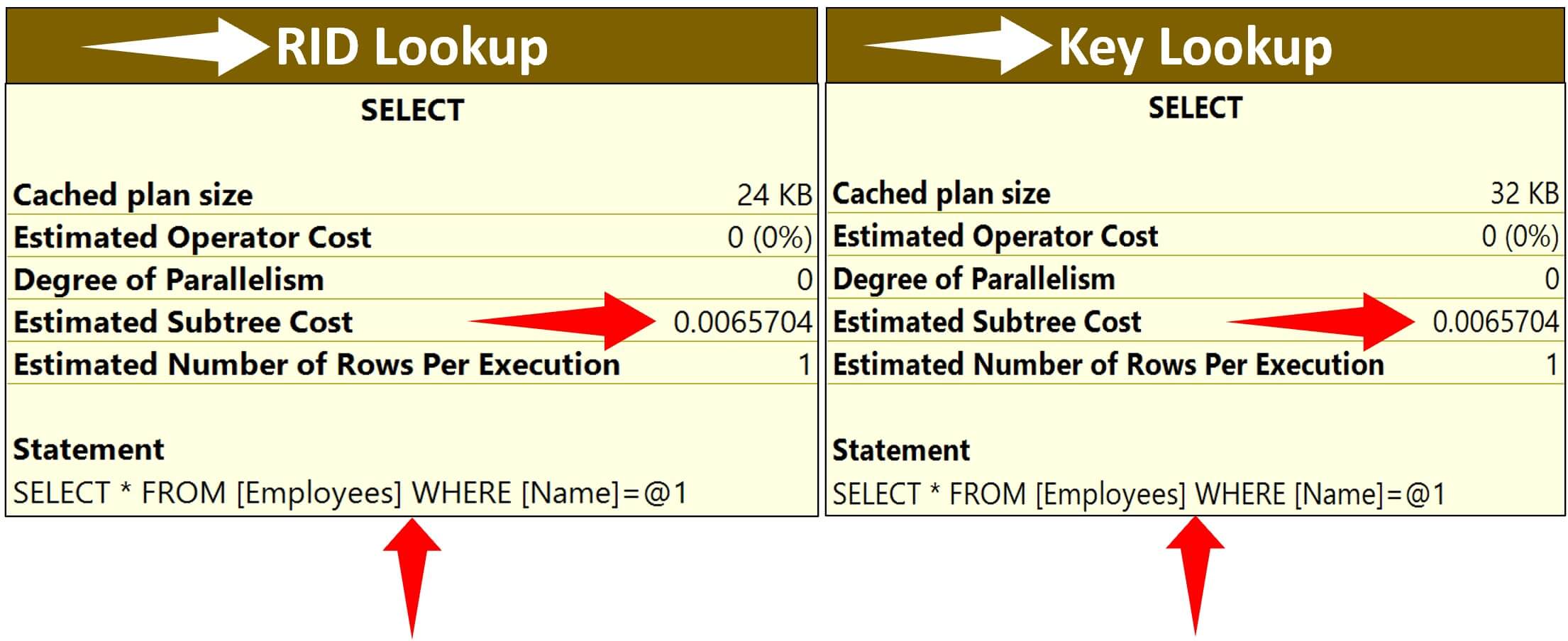
Which one yields better performance really depends on several factors like
- What the query is trying to do
- The columns you have in the index and the select list of your query
- Data distribution etc
Only by testing and looking at the stats can tell us which yields better performance.


© 2020 Pragimtech. All Rights Reserved.